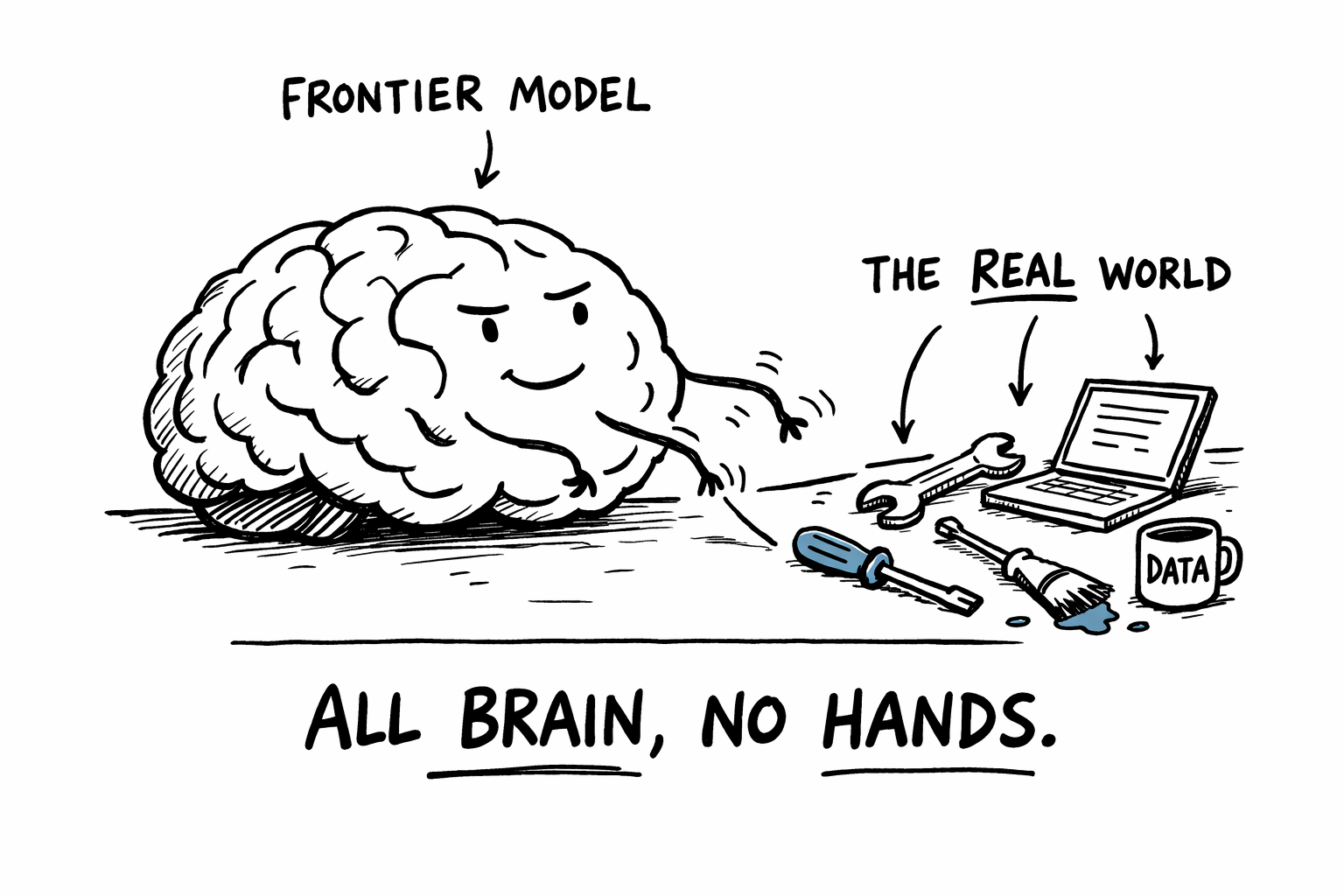
Anthropic built one of the most capable AI models in the world. Then they asked it to build a complex application from scratch.
It failed. Tried to do everything at once, declared victory too early, produced something broken.
So they wrapped better scaffolding around the same model. Progress tracking, incremental task lists, session handoffs, automated testing. Same brain, better hands. The second attempt worked.
That scaffolding has a name: a harness. And it might be the most under-discussed idea in AI right now.
Every few months a new model drops and the headlines write themselves. Claude 4. GPT-5. Gemini 2.5. The media covers foundation models like they're the whole story. But the real gains, the ones changing what AI can actually do in practice, are happening in the harness. The tooling and orchestration wrapped around the model. An entire discipline evolving at breakneck speed, and almost nobody outside builder circles is paying attention.
The Brain and the Hands
Think of a master watchmaker. What makes them extraordinary isn't their knowledge of horology or their dexterity. It's both. Their brain is judgment and planning. Their hands are the tools, the workbench, the physical ability to execute.
A brilliant brain without skilled hands produces nothing. Skilled hands without a brain just flail around.
In AI, the brain is the foundation model. The reasoning, the ability to understand what you're asking and figure out how to approach it.
The hands are everything that lets the model actually do things. The tools it can call, the memory it carries across sessions, the context it receives, the verification systems that catch mistakes, the logic that breaks complex work into smaller pieces. That's the harness.
 Same brain. Very different outcomes.
Same brain. Very different outcomes.
Both sides have gotten dramatically better in two years. Models went from party tricks to genuine reasoning engines. Harnesses evolved from simple prompt templates to systems with persistent memory, tool use, multi-agent coordination, and self-verification loops.
The best AI workflows are the ones where both the brain and the hands are strong. And well-matched.
What's Inside a Harness
The harness is everything between the brain and the outside world.
System prompt. Before the model sees your request, it receives a briefing: who it is, what it's good at, what to avoid, how to format responses. Like an onboarding document that gets re-read before every single task. The same model with a different system prompt feels like a completely different product.
Context. The model can only work with what it can see. A model answering a question about your codebase is only as good as the code you show it. Every token in the window matters. Putting the right information in front of the model at the right time is the core skill of harness engineering. Practitioners call this context engineering, and it's the hardest part to get right.
Tools. A raw model can only generate text. Give it tools and it can search the web, read files, write code, call APIs, send messages. Tools are what turn a chatbot into an agent.
Memory. Models are stateless. Once a conversation ends, everything is gone. Memory systems give agents persistence: short-term memory tracks what happened within a session, long-term memory carries knowledge across sessions. Anthropic's fix for their failing agent was exactly this, progress files committed to git, structured state that survived session boundaries.
Memory is the difference between an agent that starts from scratch every time and one that builds on its own work.
Orchestration. For anything beyond a single question-and-answer, something has to manage the workflow. Break a complex task into steps. Decide what to do next based on what just happened. Retry when something fails. Hand off between specialized sub-agents. The simplest pattern is a loop: act, observe, update the plan, act again.
Retrieval. Most useful knowledge doesn't fit in the context window. Retrieval systems, often called RAG, search through your documents and pull in only what's relevant. It's how you give a model access to your company's entire documentation without pasting it all in every time.
Verification. Left unchecked, models make confident mistakes. Verification systems catch them: automated tests on generated code, linters that enforce boundaries, validators that flag contradictions. The best harnesses build verification into every step rather than checking only at the end.
None of these are especially complex on their own. The difficulty is combining them well. That's what separates a demo from a product.
Harness engineering is never finished. Mitchell Hashimoto, who coined the term, describes it as a loop: every time an agent makes a mistake, you engineer a fix so it never makes that mistake again.
Every failure becomes infrastructure.
OpenAI learned this building a million-line application entirely with AI agents, zero hand-written code. Their biggest lesson wasn't about the model. The agent struggled not because it was incapable, but because the harness was underspecified. Give the agent a concise map of what matters, not a thousand-page manual. Context is a scarce resource. Flooding it hurts more than it helps.
There's a counterintuitive pattern here: constraining agents makes them more reliable. Fewer architectural choices, enforced boundaries, standardized structures. You trade some flexibility for outputs you can actually trust.
The harness isn't just enabling the model. It's deliberately limiting it.
Go deeper on harnesses
- Effective Harnesses for Long-Running Agents — Anthropic's engineering team on solving multi-session agent work with progress tracking and incremental feature delivery.
- Harness Engineering — OpenAI's report on building a million-line app with zero hand-written code and every lesson they learned doing it.
- My AI Adoption Journey — Mitchell Hashimoto (creator of Terraform) coined the term and explains the core loop: every agent failure should become infrastructure.
- Harness Engineering — Martin Fowler's team breaks harnesses into three pillars: context engineering, architectural constraints, and entropy management.
- The Importance of Agent Harness in 2026 — Phil Schmid expands his CPU/OS analogy with practical patterns for building harnesses that outlast model upgrades.
- Agentic Engineering Patterns — Simon Willison's practitioner guide to testing, orchestration, and code comprehension patterns for agent workflows.
The Performance Triangle
Once you see AI as brain plus hands, the next question is practical: how do you pick the right combination for a specific job?
Three dimensions.
Quality is how good the output is on the first try. Can you trust it without spending time fixing it?
Cost is how much you pay per completed task. Not per token, per task. A cheap model that needs three rounds of correction often costs more than an expensive one that nails it first try. Inference costs drop roughly an order of magnitude per year, which helps.
Latency is how long it takes. For chatbots and voice apps, users notice delays above a second. For code generation or batch processing, total generation speed matters more.
You can rarely optimize all three at once. Improving one almost always costs you another.
 Pick two. Tradeoffs are necessary.
Pick two. Tradeoffs are necessary.
High quality and low latency? Expensive, you're running the biggest model on dedicated hardware. High quality and low cost? Slow, you're batching requests and waiting for off-peak pricing. Low cost and low latency? A small, fast model that makes more mistakes.
The right balance depends entirely on the task. Production code that ships to customers? Optimize for quality, being wrong is expensive. Real-time chat interface? Latency is king. Coding agent running overnight while you sleep? Cost is all that matters. Nobody's waiting.
As models and harnesses keep improving, the triangle keeps shifting. What needed a frontier model last year now runs fine on a smaller, cheaper one.
These two ideas work as a pair. Brain-and-hands tells you where to invest: is the bottleneck the model's reasoning or the harness around it? The performance triangle tells you what to optimize for once you've found the bottleneck.
This is what makes tools like Claude Code, Codex, and Antigravity feel so different from a year ago. They're not just running better models. They ship with actual hands, harnesses that read your files, run your tests, remember what they tried, and course-correct when something breaks.
The brain was already good enough. The hands are what changed everything.
Written with ❤️ by a human (still)