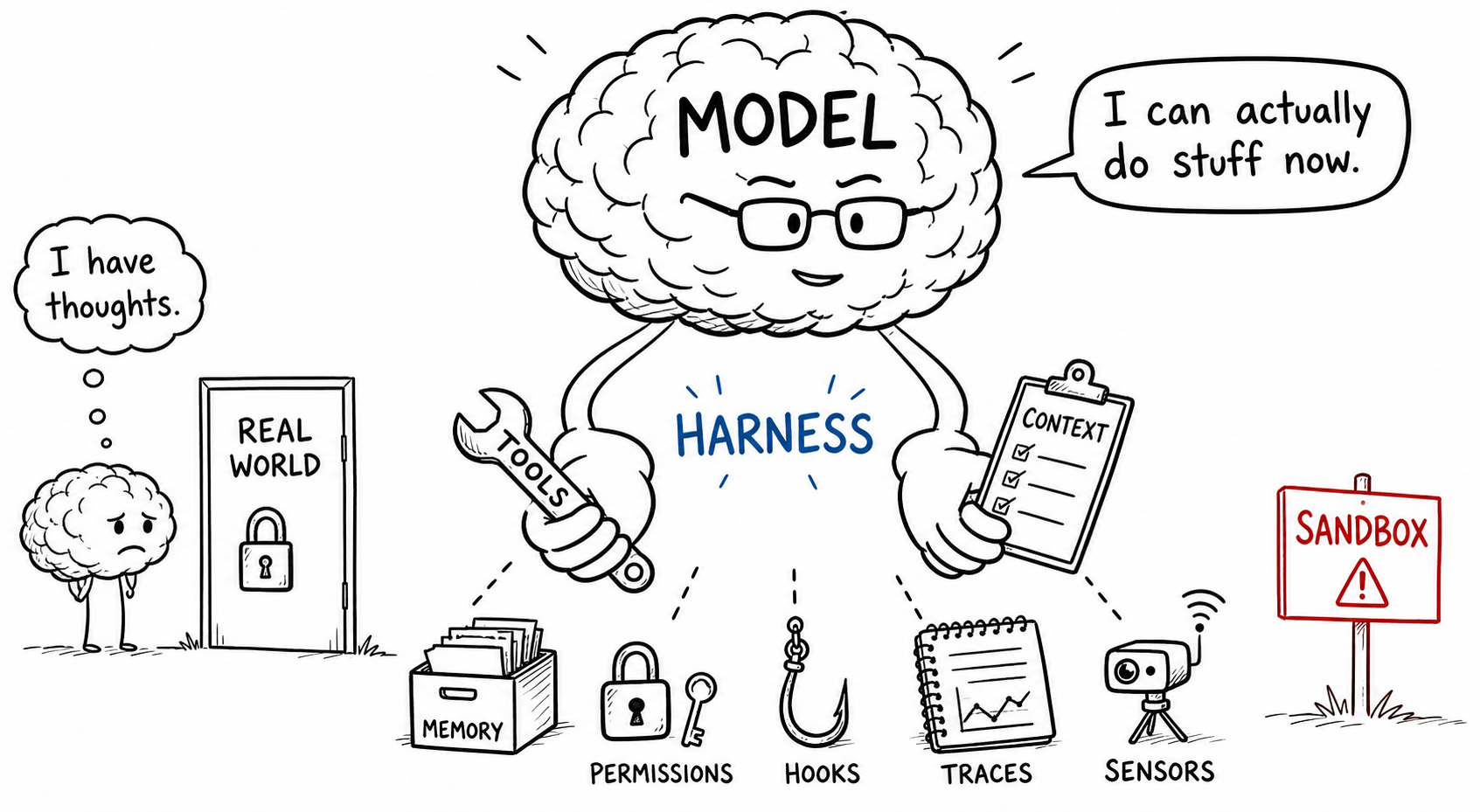
OpenAI shipped an essay in February 2026 called Harness Engineering. Three engineers, ~1M lines of production code, ~1,500 PRs merged, zero hand-typed code. The essay itself was about the scaffolding around the model:
🛠️ tools · 🗂️ context · 🔒 permissions · 📦 sandbox · 📊 evals · 💾 memory · 🪝 hooks · 🔍 traces
I've spent the last couple of months building Darius, a harness for knowledge workers rather than engineers. To do that I first had to reverse-engineer every serious coding harness on the market and figure out which parts transfer and which don't. Claude Code, Codex, Cursor, Cline, Windsurf, half a dozen others. What surprised me after months of staring at agent configs was how identical everything looked under the hood. Different file formats, slightly different names, but the same eight components doing the same eight jobs in every serious product.
I believe models will commoditize eventually. Intelligence is going to be sold by the input/output token the way electricity is sold by the kilowatt-hour. We'll pick different models depending on the task (I've written about model personality here), but what makes a great product is going to come from the harness.
Brain and hands
The mental model I keep coming back to is a brain and a pair of hands.
The brain is the foundation model, the thing that does the actual cognition. The hands are everything around the brain that lets it touch the real world. That covers the tools the model can reach for, the memory it carries from session to session, the context the harness loads in on every turn, and the various systems that catch the model when it gets something wrong. Both halves have gotten much better since 2024. The brain improvements are what get benchmarked and what get the press coverage. The hands improvements are quieter, and they're where most of the felt difference in using these tools has actually come from.
There's a line in Anthropic's Managed Agents post that I keep returning to: harnesses encode assumptions that go stale as models improve. Once you say it that way, a lot of the picture clicks into place. The brain keeps getting smarter and the hands keep being rebuilt around the smarter brain. Harness engineering is a job that never really finishes, partly because of that.
Phil Schmid uses a different framing, which is that the model is the CPU and the harness is the operating system. Same observation, different metaphor. The OS is where the experience of using a computer actually lives, even though almost nobody who uses a computer ever interacts with the CPU directly.
The harness for the rest of us
There are roughly 30 million professional developers in the world (some estimates go up to 48 million if you count anyone who codes) and roughly a billion knowledge workers. Yet every serious harness shipped between 2024 and 2026 was built for technical people. There's a fair reason for that. Code is verifiable. You can run tests against it, run a build, lint it, type-check it, diff it, and tell within seconds whether the output is broken or working. Harness engineering grew up in code because code had the cleanest feedback loops, and feedback loops are what make those coding agentic workflows feel magical.
But the components inside a harness aren't actually coding-specific. The same eight pieces (which I'll walk through in the next section) describe any agent doing any kind of work. The same shape that shows up in Claude Code shows up in problems with nothing to do with code: a lawyer drafting redlines, a salesperson writing follow-ups, an ops lead deciding which Linear ticket to escalate. The mechanics are the same but the substrate is different. There is a huge market waiting for a solution and we are just at the infancy.
 Coding was the first vertical. The next ones are a lot bigger.
Coding was the first vertical. The next ones are a lot bigger.
What's actually inside a harness
If you build one of these things, you end up with roughly eight parts. The list is stable across products to a degree that surprised me when I first noticed it. Claude Code has these. Codex has these. Cursor, Devin, Replit, Vercel's v0, all the same components, with slightly different names and slightly different emphasis. (This is the part I spent months mapping while building Darius.)
 The eight parts of a serious agent harness.
The eight parts of a serious agent harness.
🪪 System prompt. What the agent thinks it is. The same underlying model with a different system prompt feels like a different product, which is one of those things people don't quite believe until they see it. Run Claude Code's prompt and Codex's prompt against the same underlying model and you get two pretty different personalities, one a bit iterative and anxious, the other more methodical and patient. Most of what users experience as 'the personality' of a coding tool is coming from this layer.
🗂️ Context manager. The model can only work with what it can see in its window, and every token in that window costs something, either money or attention. The context manager decides what to put in front of the model and when, and how to keep useful things in the window as the conversation gets long. Compaction, retrieval, summarisation, deciding what to drop. Drew Breunig has a useful taxonomy of how this fails, four modes he calls poisoning, distraction, confusion, and clash. If you've watched a long agent session degrade into nonsense, it'll usually be one of those four.
🛠️ Tool registry. What the agent can call. grep, git, run a test, edit a file, send an email, file a ticket, query a CRM. Ken Aizawa at Anthropic has the canonical piece on this, and his framing is that tools designed for agents have to be different from tools designed for humans, and different again from APIs designed for other software. The consumer is probabilistic and slightly weird, so the tool has to be shaped accordingly.
💾 Memory and state. What survives a context reset. AGENTS.md, SKILL.md, CLAUDE.md, the various progress files long-running agents write to themselves. Mostly flat text. Mostly version-controlled. Mostly hand-edited by humans. Anthropic's two-agent harness uses an initializer agent that writes a claude-progress.txt file, and the coding agent then picks up wherever the initializer left off. The file is the bridge between sessions.
🔒 Permission and sandbox. What the agent is allowed to do, and what stops it when it tries to do something stupid. Claude Code uses bubblewrap on Linux and Seatbelt on macOS. OpenAI wrote a whole separate post on what it took to build the equivalent for Windows (Windows had no clean equivalent and they had to invent one). Vercel built their sandbox on Firecracker microVMs. This is the layer that decides whether your agent can wipe your home directory or send an email to your CEO without your involvement.
🪝 Hooks. Things that fire when other things happen. Pre-commit, pre-send, pre-edit. The same shape as git hooks or webhooks, just inside the agent loop instead of outside it. They're how humans inject rules at specific points without having to rewrite the loop.
📡 Sensors. Things that catch the agent's mistakes. In coding harnesses these look like linters, type checkers, tests, Semgrep, dependency rules, mutation testing. The Thoughtworks team has the most useful piece I've found on this. Sensors are the feedback half of the loop, and the loop is roughly what turns an unreliable agent into a reliable one over time.
🔍 Traces and observability. What you can see after the fact. What the agent saw, what it decided, what tool it called, what came back. Traces are how you debug an agent and they're also the raw material for turning one bad session into a permanent rule that prevents future versions of the same session.
That's the eight, and each one is its own small discipline at this point. The reason the field is moving so fast is that the labs publish, the practitioners blog, the conference talks accumulate, and you can mostly read your way to a working understanding of any individual component.
For knowledge work, six of those eight transfer without any modification. System prompt mechanics are identical. Context manager is identical. Memory layer is identical, just with a different filename (AGENTS.md becomes VOICE.md or DECISIONS.md or OPERATING_PRINCIPLES.md, depending on what the org cares about). Hooks and observability transfer unchanged. So does the compounding loop where every failure becomes a permanent rule in AGENTS.md (the harness grows, the model gets replaced, the rules survive). That loop matters more outside code than inside it, actually, because knowledge-work mistakes tend to be more expensive on the second occurrence. A bad email sent to a customer can't be reverted with two keystrokes the way a bad commit can.
The other two components are where the actual work is, and they're hard in different ways.
The first hard problem: the SaaS filesystem
A coding harness calls grep, git, npm test, edits a file on disk. A knowledge-work harness has to call Gmail, Calendar, Notion, Linear, Slack, Salesforce, Stripe, HubSpot, Drive, Figma, plus another ten tools depending on the company. There's no single filesystem. The 'repository' of a knowledge worker is spread across ten to thirty SaaS products, each with its own auth, its own rate limits, its own data model, and no equivalent of git log to tell you what changed when.
 The 'codebase' of a knowledge worker is forty SaaS tools that don't actually talk to each other.
The 'codebase' of a knowledge worker is forty SaaS tools that don't actually talk to each other.
The local filesystem doesn't disappear in this world, by the way. Knowledge workers still download, screenshot, export, attach. The harness's own memory layer (the VOICE.md and DECISIONS.md files and so on) lives on disk for the same reason AGENTS.md does in coding harnesses. Sensitive drafts start local. Cache and scratch space stay local. What shifts is that the local filesystem stops being the canonical record of the work. The deal lives in Salesforce now. The decision lives in Slack. The meeting outcome lives in Notion. The local filesystem becomes a working surface, similar to how it functions for coding work, but it stops being the source of truth for the organisation's state.
So the question coding harnesses ask all day (what's actually in the codebase?) gets a clean answer in a hundred milliseconds because grep and glob work. Boris Cherny made the point that for Claude Code, classic file search beats RAG most of the time. The same question asked of a knowledge-work harness doesn't have a clean answer, because the 'codebase' is forty different products that don't actually talk to each other in any organised way.
What the field needs, and what mostly doesn't exist yet, is a unified context fabric across SaaS tools. Auth, normalisation, sync, caching, conflict resolution. This is straightforward infrastructure work, and anyone who's built a customer data platform or an ETL pipeline knows the shape of the problem already. The wrinkle is the consumer. The consumer for this kind of pipeline used to be dashboards and warehouses, and now the consumer is an agent that needs to know in real time what your team decided in Slack yesterday and how that bears on the deal in Salesforce today. Whoever ends up building that fabric sits underneath every knowledge-work agent the industry ships. It's the layer where I'd most expect a quiet billion-dollar infrastructure company to emerge in the next few years.
This is also where most of my time at Darius actually goes. The agent loop is the easy part. Pulling clean, current, usable context out of forty SaaS tools that were never designed to share is the actual product, and on most days the only one that matters.
The second hard problem: sensors without unit tests
A unit test runs in milliseconds and tells you pass or fail. A strategy memo doesn't tell you anything that fast. Neither does a board update or a cold email. The whole sensors idea from coding harnesses (Semgrep, ESLint, dependency rules, mutation testing) has no off-the-shelf equivalent for knowledge work, and I think inventing sensors for non-code work is the most important engineering problem in this whole field over the next two or three years.
A rough list of the kinds of things sensors have to detect:
Factuality, meaning does this claim line up with what's in our CRM and our docs and our prior emails. A hallucinated revenue number in a board deck is the kind of mistake that ends careers.
Voice fit, meaning does this draft sound like us or does it sound like a generic AI in a suit. Generic AI prose is increasingly the most reliable signal of low effort, and there's a real product in detecting it before it ships out the door.
Recipient fit, meaning is the tone right for this specific person given the last twenty interactions the company has had with them. A note to your CTO has a different shape than a note to your investor and the harness should know that without you having to spell it out.
Completeness, meaning does this doc cover what a doc of this kind has to cover. A weekly business review with no risks section is incomplete by convention and a good harness should flag it.
Consistency with prior decisions, meaning does this contradict something the org already decided three months ago. The CRM and the doc store both have organisational memory, and the harness should refuse to let new artifacts trample old commitments.
Sensitivity, meaning is there a name or a number or a commitment in here that shouldn't leave the room. The most expensive harness failures over the next few years will probably come from content policy issues rather than capability issues.
Each of those is a real research problem in its own right, and each is also a product opportunity. Building this sensor stack is most of what I do at Darius day to day, and the order of priority above is roughly the order we tackled them in. The implication is roughly that knowledge-work harnesses without good sensors are too dangerous to ship at scale, while coding harnesses without sensors are mostly just annoying. The first vertical winners will be the teams that take sensors seriously from day one.
A few other smaller differences
Permissions have to be more conservative because mistakes don't revert. A bad commit gets reverted with two keystrokes. A bad email to a customer doesn't, a meeting note that overwrites a decision doesn't, an outbound Slack message in the wrong channel doesn't. The blast radius of knowledge-work actions is lopsided in the way that matters: small upside on autonomy, large downside on irreversible mistakes. So the default has to flip toward draft-first, with humans in the loop on anything irreversible.
Taste matters more than correctness once you leave code. A memo is well-judged or poorly-judged rather than right or wrong. Generic 'be professional' prompting is 2023-era stuff and it doesn't produce work that hits the bar at most companies. The new primitive is encoded taste as a first-class artifact in the harness. A VOICE.md with annotated examples of good and bad drafts and the reasons why. A DECISIONS.md that captures the org's reasoning style. The memory layer is the same shape as in coding (flat files the harness reads on every turn) but the surface is much bigger. For a coding agent, you can hand-write AGENTS.md in an hour. For a knowledge-work agent, the memory has to capture voice, relationships, prior decisions, processes, and sensitivities. Most of that can't be hand-written. It has to be learned from the org's existing emails, docs, and Slack history. Generic taste doesn't do much for anyone. The specific taste of a specific company is something competitors can't copy easily, and it compounds over time.
The unit of work changes from diffs to artifacts. Code ships as a diff against a known state. Knowledge work ships as docs, decks, emails, calendar holds, logged decisions, and each of those has a lifecycle (draft, review, revise, send, archive) that the harness has to manage as a first-class concept. Git gave coding harnesses the lifecycle infrastructure for free. Knowledge work has nothing equivalent, so the harness has to build the lifecycle itself.
Coding harnesses were the first generation because they were always going to be. Code is verifiable, code lives on a filesystem, code has a single canonical history, and the people who use coding harnesses are exactly the people who'd build them. The harnesses for the rest of us are the second generation. Same eight components, six of them ported across, two of them rebuilt, the tool layer swapped out entirely, and the audience is the billion-plus people who don't write code for a living.
The agent loop is mostly solved at this point. What remains hard is the sensors and the fabric. That's the direction we're heading with Darius.
Sources
If you only have an hour on this topic, this is the shortlist I'd read.
- OpenAI, Harness Engineering: leveraging Codex in an agent-first world
- Mitchell Hashimoto, My AI Adoption Journey
- Michael Bolin (OpenAI), Unrolling the Codex agent loop
- Birgitta Böckeler (Thoughtworks), Harness engineering for coding agent users
- Walden Yan (Cognition), Don't Build Multi-Agents
- Anthropic Engineering, Effective harnesses for long-running agents
- Anthropic Engineering, Effective context engineering for AI agents
Written with ❤️ by a human (still)